Need a research hypothesis? Ask AI.
Crafting a unique and promising research hypothesis is a fundamental skill for any scientist. It can also be time consuming: New PhD candidates might spend the first year of their program trying to decide exactly what to explore in their experiments. What if artificial intelligence could help?
MIT researchers have created a way to autonomously generate and evaluate promising research hypotheses across fields, through human-AI collaboration. In a new paper, they describe how they used this framework to create evidence-driven hypotheses that align with unmet research needs in the field of biologically inspired materials.
Published Wednesday in Advanced Materials, the study was co-authored by Alireza Ghafarollahi, a postdoc in the Laboratory for Atomistic and Molecular Mechanics (LAMM), and Markus Buehler, the Jerry McAfee Professor in Engineering in MIT’s departments of Civil and Environmental Engineering and of Mechanical Engineering and director of LAMM.
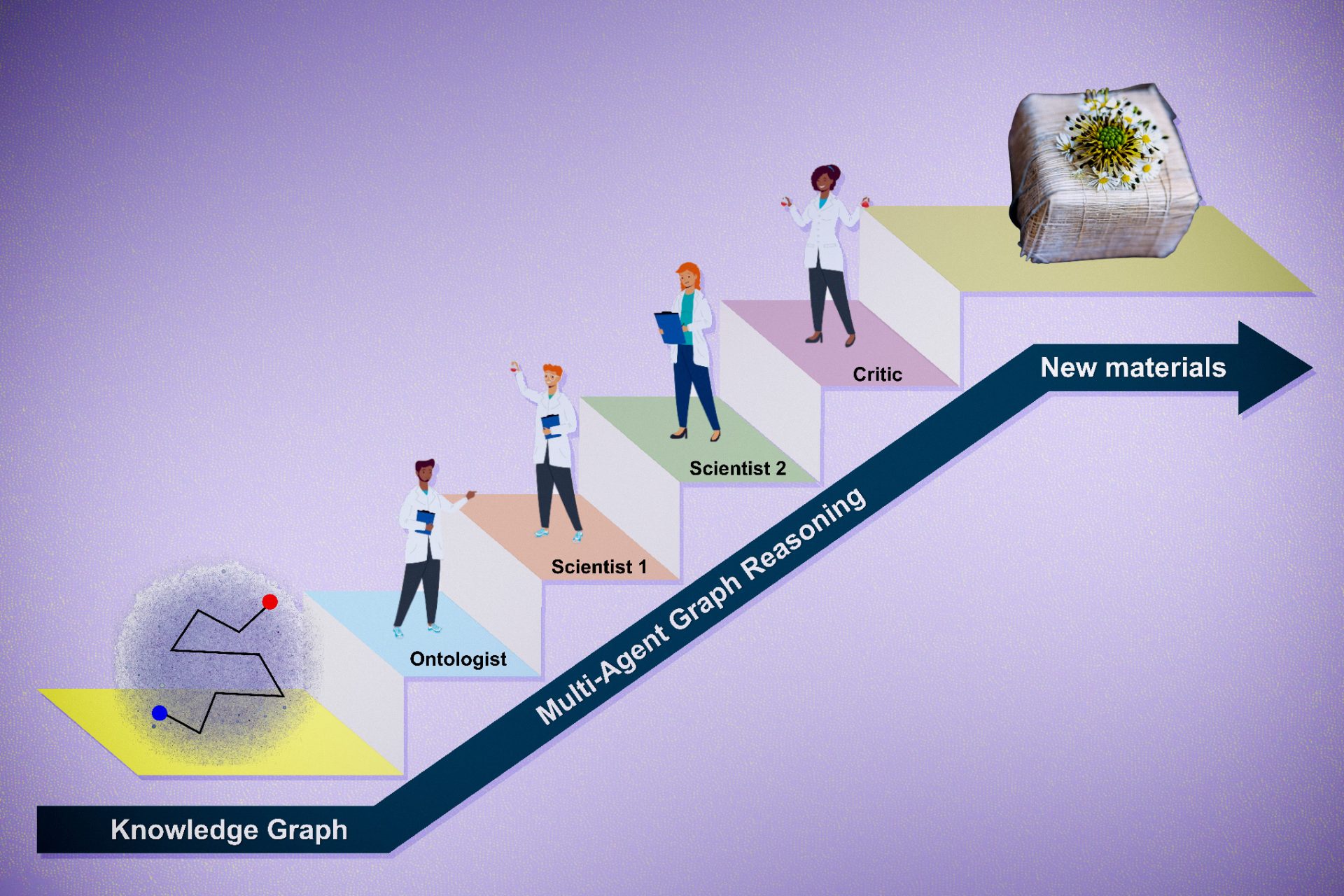
The framework, which the researchers call SciAgents, consists of multiple AI agents, each with specific capabilities and access to data, that leverage “graph reasoning” methods, where AI models utilize a knowledge graph that organizes and defines relationships between diverse scientific concepts. The multi-agent approach mimics the way biological systems organize themselves as groups of elementary building blocks. Buehler notes that this “divide and conquer” principle is a prominent paradigm in biology at many levels, from materials to swarms of insects to civilizations — all examples where the total intelligence is much greater than the sum of individuals’ abilities.
“By using multiple AI agents, we’re trying to simulate the process by which communities of scientists make discoveries,” says Buehler. “At MIT, we do that by having a bunch of people with different backgrounds working together and bumping into each other at coffee shops or in MIT’s Infinite Corridor. But that’s very coincidental and slow. Our quest is to simulate the process of discovery by exploring whether AI systems can be creative and make discoveries.”
Automating good ideas
As recent developments have demonstrated, large language models (LLMs) have shown an impressive ability to answer questions, summarize information, and execute simple tasks. But they are quite limited when it comes to generating new ideas from scratch. The MIT researchers wanted to design a system that enabled AI models to perform a more sophisticated, multistep process that goes beyond recalling information learned during training, to extrapolate and create new knowledge.
The foundation of their approach is an ontological knowledge graph, which organizes and makes connections between diverse scientific concepts. To make the graphs, the researchers feed a set of scientific papers into a generative AI model. In previous work, Buehler used a field of math known as category theory to help the AI model develop abstractions of scientific concepts as graphs, rooted in defining relationships between components, in a way that could be analyzed by other models through a process called graph reasoning. This focuses AI models on developing a more principled way to understand concepts; it also allows them to generalize better across domains.
“This is really important for us to create science-focused AI models, as scientific theories are typically rooted in generalizable principles rather than just knowledge recall,” Buehler says. “By focusing AI models on ‘thinking’ in such a manner, we can leapfrog beyond conventional methods and explore more creative uses of AI.”
For the most recent paper, the researchers used about 1,000 scientific studies on biological materials, but Buehler says the knowledge graphs could be generated using far more or fewer research papers from any field.
With the graph established, the researchers developed an AI system for scientific discovery, with multiple models specialized to play specific roles in the system. Most of the components were built off of OpenAI’s ChatGPT-4 series models and made use of a technique known as in-context learning, in which prompts provide contextual information about the model’s role in the system while allowing it to learn from data provided.
The individual agents in the framework interact with each other to collectively solve a complex problem that none of them would be able to do alone. The first task they are given is to generate the research hypothesis. The LLM interactions start after a subgraph has been defined from the knowledge graph, which can happen randomly or by manually entering a pair of keywords discussed in the papers.
In the framework, a language model the researchers named the “Ontologist” is tasked with defining scientific terms in the papers and examining the connections between them, fleshing out the knowledge graph. A model named “Scientist 1” then crafts a research proposal based on factors like its ability to uncover unexpected properties and novelty. The proposal includes a discussion of potential findings, the impact of the research, and a guess at the underlying mechanisms of action. A “Scientist 2” model expands on the idea, suggesting specific experimental and simulation approaches and making other improvements. Finally, a “Critic” model highlights its strengths and weaknesses and suggests further improvements.
“It’s about building a team of experts that are not all thinking the same way,” Buehler says. “They have to think differently and have different capabilities. The Critic agent is deliberately programmed to critique the others, so you don’t have everybody agreeing and saying it’s a great idea. You have an agent saying, ‘There’s a weakness here, can you explain it better?’ That makes the output much different from single models.”
Other agents in the system are able to search existing literature, which provides the system with a way to not only assess feasibility but also create and assess the novelty of each idea.
Making the system stronger
To validate their approach, Buehler and Ghafarollahi built a knowledge graph based on the words “silk” and “energy intensive.” Using the framework, the “Scientist 1” model proposed integrating silk with dandelion-based pigments to create biomaterials with enhanced optical and mechanical properties. The model predicted the material would be significantly stronger than traditional silk materials and require less energy to process.
Scientist 2 then made suggestions, such as using specific molecular dynamic simulation tools to explore how the proposed materials would interact, adding that a good application for the material would be a bioinspired adhesive. The Critic model then highlighted several strengths of the proposed material and areas for improvement, such as its scalability, long-term stability, and the environmental impacts of solvent use. To address those concerns, the Critic suggested conducting pilot studies for process validation and performing rigorous analyses of material durability.
The researchers also conducted other experiments with randomly chosen keywords, which produced various original hypotheses about more efficient biomimetic microfluidic chips, enhancing the mechanical properties of collagen-based scaffolds, and the interaction between graphene and amyloid fibrils to create bioelectronic devices.
“The system was able to come up with these new, rigorous ideas based on the path from the knowledge graph,” Ghafarollahi says. “In terms of novelty and applicability, the materials seemed robust and novel. In future work, we’re going to generate thousands, or tens of thousands, of new research ideas, and then we can categorize them, try to understand better how these materials are generated and how they could be improved further.”
Going forward, the researchers hope to incorporate new tools for retrieving information and running simulations into their frameworks. They can also easily swap out the foundation models in their frameworks for more advanced models, allowing the system to adapt with the latest innovations in AI.
“Because of the way these agents interact, an improvement in one model, even if it’s slight, has a huge impact on the overall behaviors and output of the system,” Buehler says.
Since releasing a preprint with open-source details of their approach, the researchers have been contacted by hundreds of people interested in using the frameworks in diverse scientific fields and even areas like finance and cybersecurity.
“There’s a lot of stuff you can do without having to go to the lab,” Buehler says. “You want to basically go to the lab at the very end of the process. The lab is expensive and takes a long time, so you want a system that can drill very deep into the best ideas, formulating the best hypotheses and accurately predicting emergent behaviors. Our vision is to make this easy to use, so you can use an app to bring in other ideas or drag in datasets to really challenge the model to make new discoveries.”
Share on Bluesky